AI's reasoning quandary
As debates swirl around plateauing LLM performance, "reasoning" paradigms are hailed as the next frontier for technological & commercial growth.

Through tools like ChatGPT, we’ve all experienced the impressive power of LLMs across various use cases from natural language tasks and multimodal applications. However, we’ve also witnessed numerous examples of LLMs hallucinating and faltering when performing tasks that require “reasoning”.
For instance, LLMs struggle with formal reasoning in large arithmetic problems and chess strategy. Even the most advanced LLMs struggle with straightforward logical reasoning tasks like the “Alice in Wonderland” problem.
Hallucinations and reasoning failures are seemingly inherent in the current offering of LLMs, with several critics pointing to underlying transformer architecture as the cause for these limitations. At its core, the two major building blocks of transformers are positional encoding and self-attention, which make transformers particularly suited for pattern matching and statistical inference.
In short, transformers are good at probabilistically predicting the next element in a sequence in order to generate a response, which is distinct from having a true understanding of concepts for first principle reasoning. Hence, LLMs have been dubbed everything from an “n-gram model on steroids” to “stochastic parrots”, rather than true cognitive engines that can reason like humans.
But what’s the hullabaloo over whether LLMs can formally reason or not, especially if everything ends up looking like “reasoning” anyway? This debate is top of mind for many industry observers who perceive advanced reasoning as a necessary condition for AGI. But as a VC focused on B2B, I ponder about this question more from an enterprise perspective, since the reasoning gap presents friction to enterprise adoption.
For instance, higher levels of hallucination could arise from a lack of formal reasoning, limiting the adoption of AI in industries such as financial services and healthcare, which have an extremely low error tolerance. Additionally, enterprises have built up large corpuses of information, and DeepMind researchers showed that frontier models are universally limited when conducting long-context reasoning tasks:
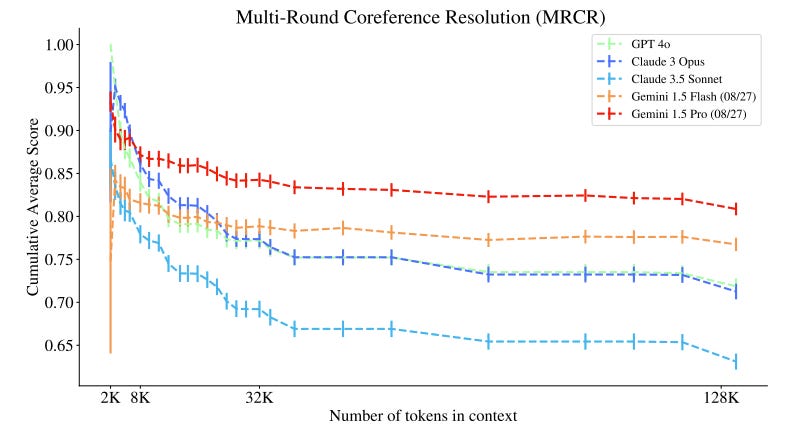
Source: Vodrahalli et al., “Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries” (9/19/24)
With the race to complex reasoning emerging as the next big frontier for AI, OpenAI’s launch of o1 in September generated tremendous buzz, since o1 was touted to be a front runner in demonstrating “human-like reasoning”. Unlike previous models that focus compute on pre-training, o1 emphasizes inference-time scaling. This enables it to generate a long internal chain of thought before responding, seemingly unlocking advanced reasoning capabilities:

Source: Tweet from @DrJimFan
However, researchers from Apple were quick to challenge these “reasoning” assertions. Through the GSM-Symbolic benchmark, these researchers demonstrated that current LLMs, including the o1 series, lack genuine logical reasoning capabilities. Instead, current models replicate reasoning steps observed in their training data, bringing us back to square one in the AI reasoning debate:
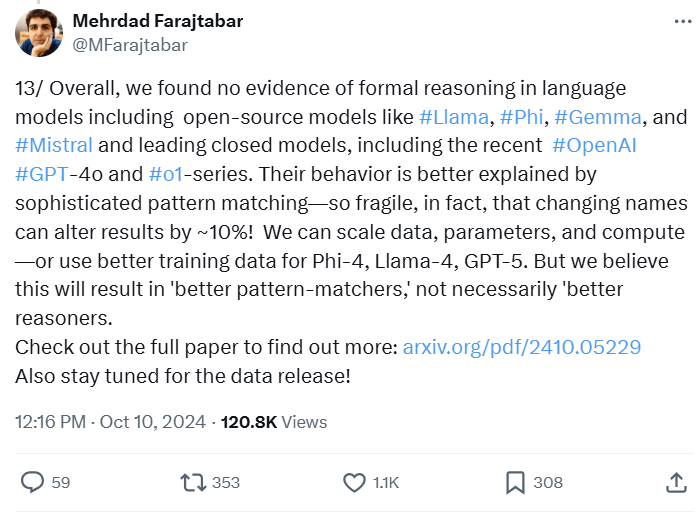
Source: Tweet from @MFarajtabar
The debate around the reasoning capabilities of the current cohort of AI models has been more heated recently amidst the backdrop of LLM performance improvements potentially hitting a plateau. This observation has been top of mind for many in the AI community, in part due to discourse around diminishing returns in LLM pre-training scaling laws — where using more data and compute power in the LLM pretraining stage may not necessarily continue to result in commensurate performance gains.
o1’s unveiling and the model’s focus on inference-time scaling had attracted a lot of attention as it was one of the first examples of how state-of-the-art “reasoning” paradigms could be a new way for companies to drive sustained technological and commercial growth. However, these paradigms are perhaps not the magic bullet that the industry is making them out to be if reasoning qualifications are dramatically overblown.
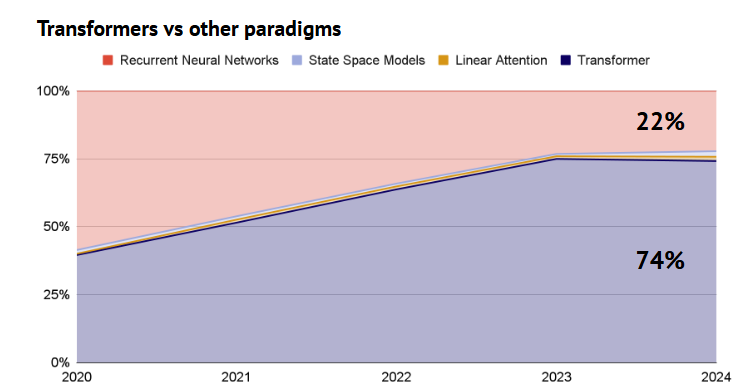
Source: Nathan Benaich, “State of AI Report 2024” (10/10/24)
I’ll end by putting forth that transformers currently represent the dominant paradigm in deep learning (chart above), but the inherent reasoning limitations of LLMs due to fundamental architecture nuances could present a window for new architectures to challenge the transformer’s reign, especially as structured reasoning capabilities emerge in other architecture forms. Additionally, if the reasoning quandary lingers, this could also open up and sustain wedges of opportunity for AI infrastructure companies focused on optimizing the last-mile.
This article was originally published here.
